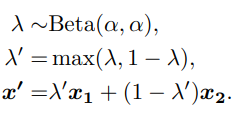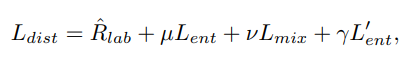https://openaccess.thecvf.com/content/CVPR2022/papers/Zhao_Dist-PU_Positive-Unlabeled_Learning_From_a_Label_Distribution_Perspective_CVPR_2022_paper.pdf
Introduction
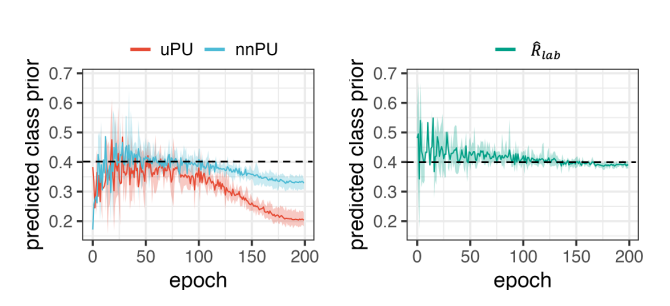
PUのCost-sensitiveの研究は、Negative Assumptionといって過度にデータをNegativeに分類させてしまう。以下のように、全体の割合の0.4から大きく逸脱することになる。
なので、U Dataについての予測した各サンプルのスコアの平均とClass Priorが大きく逸れないようにしたい。だが、明示的な解としてすべてのUの予測がπになってしまうのがあるので、それを防ぐためにEntropyの項をつけた。
Methodology
- x∈X⊆Rdで、Ground Truthのラベルy=1はPでy=0がN。
- 2setのいずれでも問題はない。
Cost-sensitiveの式で導いた時、
- Pの部分のcalibrateされた予測値の和は1にならないといけない。
- Uの部分のcalibrateされた予測値の和はπにならないといけない。
この2点がこの手法の提案の核心。
本体の式
nnPUの式は以下のようになる。
πE+[l(g(x),+1)]+∣−πE+[l(g(x),−1)]+EX[l(g(x),−1)]∣ だが、今回は以下のようなclippingをする。
2πE+[l(g(x),+1)]+∣EX[l(g(x),−1)]−π∣ 実際はg(x)の出力値をlogitとして扱いsigmoid関数fをかませて、f(g(x))がクラスの予測確率である。そして、予測したラベルは本来離散的であるべきだが、これからの計算の都合上連続的であるようにする。
具体的には、あるデータ群に対するラベルの平均は、f(g(x))の予測値の平均をとる感じである。この平均について、P全体では1に、U全体ではπになるようにしたい。
これは、以上のclippingされた式に対して、次のように目的の値からのズレで評価し、MAE損失を使う。
2πE+[l(g(x),+1)]+∣EX[l(g(x),−1)]−π∣→Rlab=2π∣E+[f(g(x))]−1∣+∣EX[l(g(x),−1)]−π∣ だが、このままではすべてのUの予測がπに収束するような自明な解に収束してしまう。これを防ぐために、以下のような選択をする。
Entropy Minimization
Uがすべてπにならなくするには、Entropy Minimizationをさせて、全体的に極端な予測を行わせるようにする。Uのすべてのデータについて行う。
s=f(g(x))Lent=−EX[(1−s)log(1−s)+slogs] Confirmation Bias
Entropy Minimizationは明確に分けるという目的を達成できるが、一方本来曖昧なものを極端に推し進めてしまうのもある。最初に間違えた予測のまま拡大されたら、まずい。
これはConfirmation Biasという。
これを解決するため、データを以下のようにMixupする。
そして、このようにMix-upしたデータに対して、以下のようにBinary Cross Entropyで損失を追加で計算する。
s′=f(g(λ′x1+(1−λ′)x2))Lmix=E(x1,x2)[λ′lbce(s′,s1)+(1−λ′)lbce(s′,s2)] これによって、曖昧なものを極端に推し進めづらくすることができる。
最後に、Mixupされたデータについても、Entropy Minimizationも行う。
全体
ということで、全体では以下のようになる。
- 本体
- 本体のEntropy Minimization。
- ミニバッチ内のMixup。
- ミニバッチ内のMixupされたデータのEntropy Minimization。
実際の実装では、
- 単純の「本体」と「本体のEntropy Minimization」だけでWarm Up。
lr=5e-4, 60epochs 走らせる。
- 「ミニバッチ内のMixup」と「ミニバッチ内のMixupされたデータのEntropy Minimization」を訓練に使う。(与えられたデータを純粋にそのまま学習に使うことはもうない)
ハイパーパラメタについては以下のように使っていた。αはmixupのパラメタ。
μ∈[0,0.1],ν∈[0,10],γ∈[0,0.3],α∈[0.1,10] スケジューラはcosineスケジューラを使った。
実験
- Adamを使用して、
lr=5e-4, weight_decay = 5e-3 - mix-upは重要。
- そこで使われるβ分布のαは適切に大きいのは重要である。
- DistPUはclass priorを間違えてもある程度強い。